
Часть 2. How-to: один проход от пробы до Postgres
Ниже — практический маршрут, который мы реально прогнали на демо. Он опирается на Онто как «мозг» процесса и на минимальный исполнительный контур (MCP → MinIO → Airflow → Postgres). Цель — предсказуемый импорт без «магии» нейросети и без лишнего трафика.
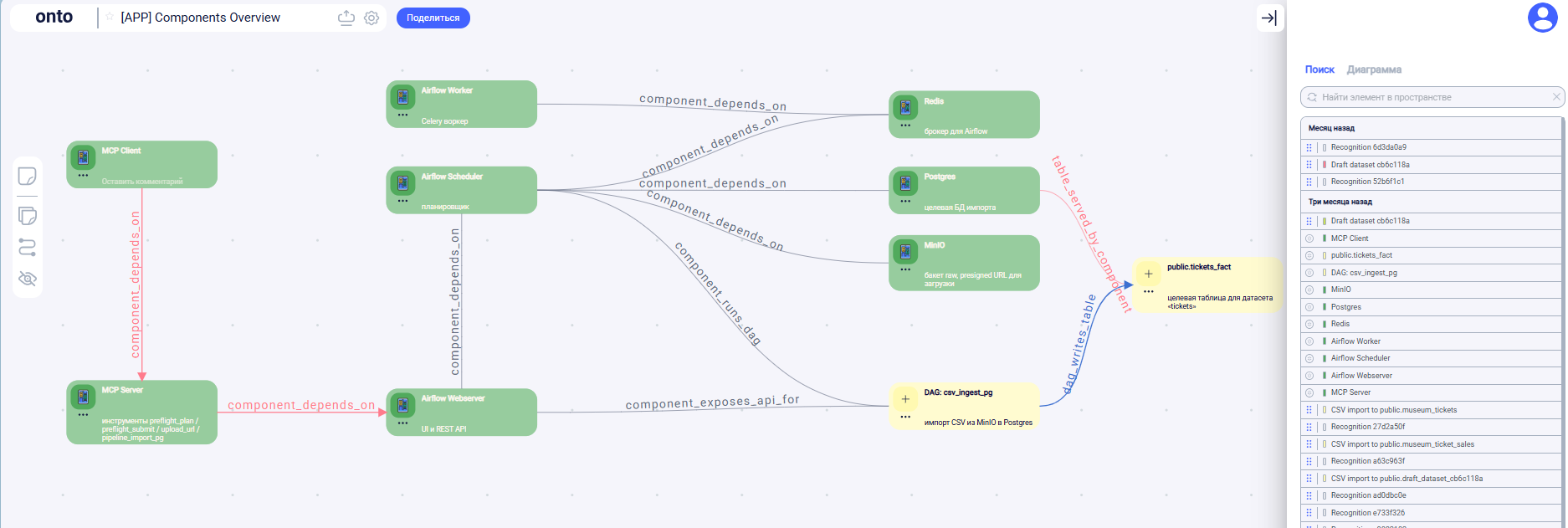
Архитектурная рамка
- Онто — хранит знания: объекты DatasetSignature, DatasetClass, PipelineTemplate, RecognitionResult и правила сопоставления.
- MCP — оркестратор шагов и API-слой (инструменты: preflight_plan, preflight_submit, upload_url, pipeline_import_pg).
- MinIO — S3-совместимое «сырое» хранилище (presigned PUT/GET).
- Airflow — один универсальный DAG csv_ingest_pg (profile → DDL → COPY → отчёт).
- Postgres — целевая БД.
MCP — оркестратор шагов и API-слой
Роль MCP. Координирует четыре шага процесса между Онто (модель знаний), MinIO (сырьё), Airflow (исполнение) и Postgres (целевая БД). Принципы: storage-first, детерминизм вместо «магии», без проксирования тяжёлых данных через сервер.
Репозиторий на гитхаб
Поток из четырёх инструментов
- preflight_plan — подготовка пробы (локально)
- MCP возвращает план для клиента: одну команду, которая локально считает «сигнатуру» файла (заголовок, хэши, базовые типы), и затем отправку этой сигнатуры обратно в MCP.
- Смысл: ничего не гоняем по сети и не грузим нейросеть ради очевидного.
- preflight_submit — анализ и решение в Онто
- MCP сопоставляет сигнатуру с объектами в Онто: если профиль (DatasetClass) найден — фиксирует выбор; если нет — создаёт аккуратный черновик. На этом же шаге жёстко выбирается хранилище (StorageConfig) и рассчитывается s3Key для загрузки.
- Смысл: маршрут определён до любых перемещений данных; решения — по алгоритмам, LLM лишь объясняет.
- upload_url — загрузка в MinIO по presigned URL
- По signatureId MCP выдаёт presigned PUT (single или multipart). Клиент заливает напрямую в MinIO, MCP байты не трогает.
- Смысл: надёжная, дешёвая загрузка без посредников и лишнего трафика.
- pipeline_import_pg — запуск импорта в Postgres
- MCP создаёт/выбирает шаблон пайплайна (если нужно) и триггерит единый DAG csv_ingest_pg в Airflow с параметрами: источник (presigned GET или {endpoint,bucket,key}), sep/encoding, target {schema, table}. На выходе — runId, статус и артефакты (DDL/отчёт).
- Смысл: один универсальный DAG, предсказуемый контракт, воспроизводимый результат.
Как это выглядит end-to-end (сверху вниз)
- Клиент запускает preflight_plan → локальная сигнатура готова.
- preflight_submit фиксирует знание в Онто и сразу определяет StorageConfig + s3Key.
- upload_url выдаёт подписи → файл попадает в MinIO
- pipeline_import_pg запускает DAG → Postgres получает таблицу, Онто — артефакты и статус.
Почему это работает в корп-среде
- Предсказуемо. Решения принимают правила (хэши, устойчивые совпадения), не «интуиция» модели.
- Бережливо. Аналитика — в локальной пробе, сервер не возит гигабайты и не «жжёт» GPU.
- Трассируемо. В Онто остаются сигнатуры, выбранные профили и шаблоны: легко объяснить «почему так».
- Экономно. Один DAG и переиспользуемые классы/шаблоны вместо «зоопарка» MVP.
Что хранит Онто — детально: что это и зачем
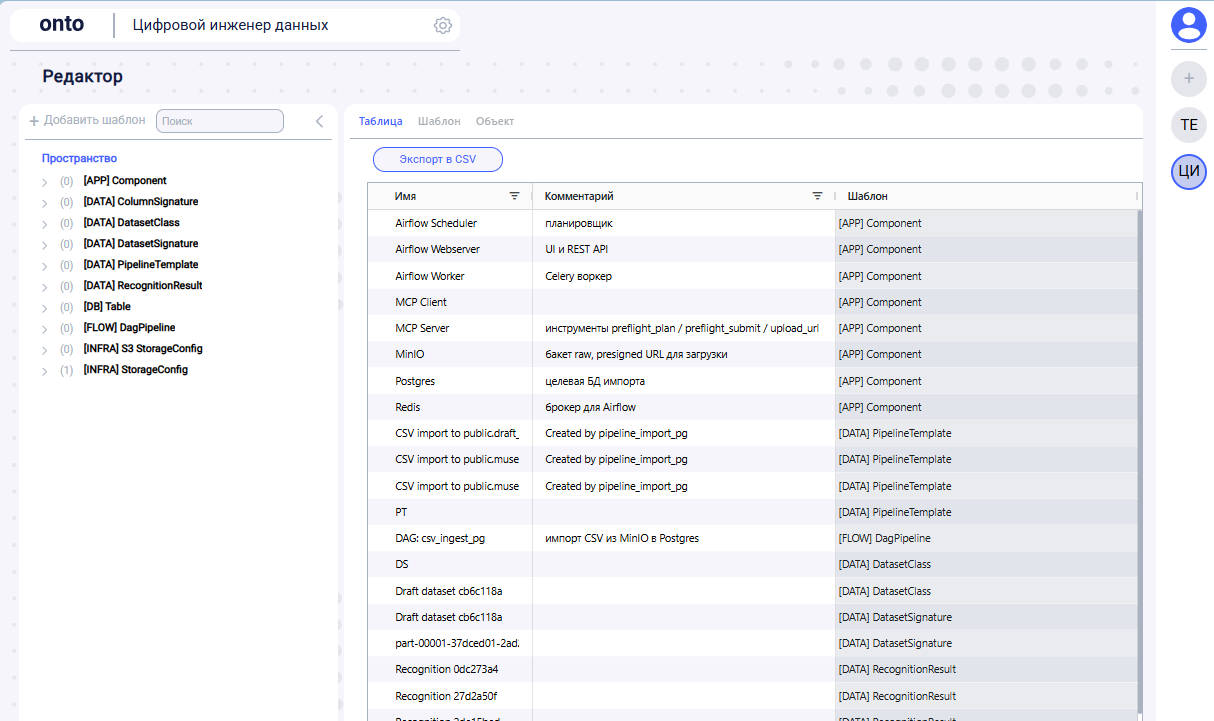
DatasetSignature
- Что это: «паспорт» конкретного файла — нормализованный заголовок, число колонок, хэши (обычный и отсортированный), разделитель, кодировка, имя/размер.
- Зачем: служит основанием для сопоставления с профилями; фиксирует параметры, по которым будет выполняться загрузка; даёт воспроизводимость («вот именно этот файл мы импортировали вот так»).
DatasetClass
- Что это: «профиль» типа датасета (не мета-шаблон, а объект): хэши и отсортированный список колонок, ключевые слова домена, флаги PII, статус draft/active.
- Зачем: определяет маршрут импорта для всех файлов такого типа; позволяет автоматически выбирать шаблон пайплайна и не изобретать логику заново при каждом новом источнике.
PipelineTemplate
- Что это: «маршрут» обработки для профиля: дефолты парсинга (sep/encoding/loadMode), целевой таргет (storage/schema/table/partitionBy), версия/статус.
- Зачем: делает импорт параметризуемым и повторяемым: один универсальный DAG + набор шаблонов, вместо «зоопарка» одноразовых скриптов; снижает стоимость поддержки.
RecognitionResult
- Что это: протокол решения сопоставления: чем именно совпало (matchedBy), с какой уверенностью (score), когда принято, краткие заметки.
- Зачем: обеспечивает объяснимость и аудит — можно ответить «почему выбран именно этот профиль/маршрут» и воспроизвести решение при повторных запусках.
Выше приведены шаблоны для создания объектов в Онто.
Что такое шаблон в Онто
Шаблон — это не «одна конкретная запись», а тип объекта с фиксированным смыслом и набором полей. Он:
- задаёт структуру (какие поля есть и как они называются);
- делает данные однородными и сравнимыми между кейсами;
- даёт точку входа для автоматизации (MCP знает, что создавать и чем заполнять);
- обеспечивает проверяемость и воспроизводимость (одни и те же правила → одни и те же решения).
Почему это важно для MCP-driven процесса
- MCP может детерминированно создавать/заполнять объекты по шаблонам (никакой импровизации в полях и названиях).
- Вся логика «почему и что делать дальше» считывается из стандартных сущностей — решение предсказуемо и защищаемо перед архитекторами.
- Шаблоны снижают стоимость поддержки: один раз договорились о форме — дальше масштабируем без переписывания «под каждый случай».
Проба: считаем сигнатуру локально (детально)
Наша цель — получить минимальный, но достаточный портрет файла без гонки трафика и без «магии». Всё делаем локально, быстрыми детерминированными правилами.
1) Что считаем (поля сигнатуры)
- encoding — кодировка чтения.
- sep — разделитель (,, ;, \t, реже |).
- hasHeader — есть ли заголовок.
- headers[] — нормализованные имена колонок.
- numCols — количество колонок.
- headerHash — sha256('h1;h2;…;hn').
- headerSortedHash — sha256('sorted(h1…hn)').
- headersSorted — строка с отсортированными именами через ;.
- dtypeGuess (по колонкам) — bool|int|float|datetime|text.
- piiFlags — phone|fio|inn|birthday|uuid (true/false).
- (опц.) rowsScanned — сколько строк просмотрели (для статистики).
2) Нормализация заголовков (строго в таком порядке)
- lower()
- strip() (обрезать пробелы по краям)
- заменить [' ', '-'] → _
- удалить все, кроме [a-z0-9_а-яё]
- схлопнуть повторные _ → один _
- убрать _ в начале/конце
Пример: " Start Date-Time " → start_date_time
3) Кодировка и разделитель
- Encoding: сначала пробуем utf-8 (срез первых 256–512 КБ). Если ошибка декодирования — пробуем cp1251. (Если хочется тонкости — локально подключаем детектор, но дефолт utf-8 чаще всего верен.)
- Sep: считаем частоты , ; \t | в первых ~256 КБ, выбираем максимум (если \t в топе — ставим табуляцию). Для спорных случаев допускаем ручную подсказку --sep.
4) Объём пробы
- Читаем только заголовок + первые N строк (обычно N=1000).
- Память не распухает, чтение идёт потоково.
- Если строки разной длины — считаем «битые» и игнорируем их при типизации.
5) Типизация колонок (простые эвристики)
Для каждого значения v (обрезанного):
- bool: true|false|0|1 (без регистра)
- int: ^-?\d+$
- float: ^-?\d+([.,]\d+)?$ (запятую не превращаем в точку — только детект)
- datetime: ISO-подобные YYYY-MM-DD, YYYY-MM-DD[ T]HH:MM(:SS)?, YYYY-MM-DDTHH:MM:SS±ZZ:ZZ
- иначе text
Выбор типа — мода по сэмплу (чаще всего встречающийся). При близких долях — text.
6) PII-эвристики (по сэмплу)
- phone: ^(7|8)?\d{10}$
- inn: ^\d{10}$
- uuid: [0-9a-f]{8}-[0-9a-f]{4}-
- birthday: ^\d{4}-\d{2}-\d{2}$ или ^\d{2}\.\d{2}\.\d{4}$
- fio (капсом, 2–3 слова кириллицей): ^[А-ЯЁ]+(?: [А-ЯЁ]+){1,2}$
Флаги поднимаем, если найдено хотя бы одно соответствие в колонке/сэмпле (или несколько — по желанию).
7) Контроль качества пробы (самопроверки)
- numCols заголовка и строк совпадают ≥ 95% в сэмпле — иначе предупреждение «пляшущие колонки».
- Дубли заголовков → автоматически переписываем name__2, name__3 и фиксируем в заметках.
- Слишком много пустых — помечаем колонку как nullableHint=true (если ведём такую метку).
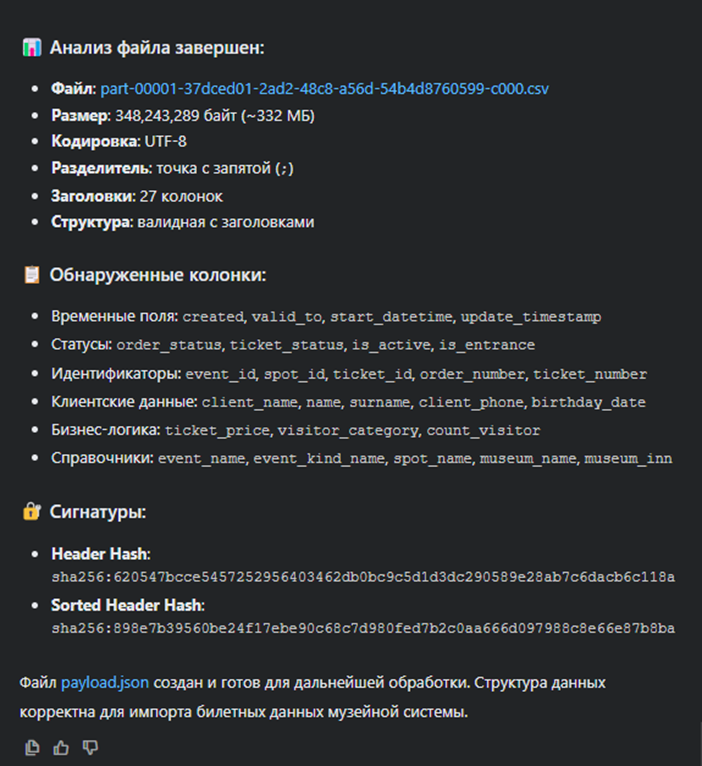
8) Формат выходного JSON (payload сигнатуры)
{
"fileName": "tickets.csv",
"fileSize": 348243289,
"signature": {
"encoding": "utf-8",
"sep": ";",
"hasHeader": true,
"numCols": 27,
"headers": ["created","order_status","ticket_status","..."],
"headerHash": "sha256:…",
"headerSortedHash": "sha256:…",
"headersSorted": "birthday_date;client_name;…;visitor_category",
"stats": {
"rowsScanned": 1000,
"dtypeGuess": { "created":"datetime","ticket_price":"float","is_active":"bool","..." },
"piiFlags": { "phone": true, "fio": true, "inn": true, "birthday": true, "uuid": true }
}
}
}
9) CLI-процедура (быстрый сценарий)
- preflight_plan возвращает одну команду shell → запускаем → получаем payload.json.
- Сохраняем рядом с файлом (или в temp).
- Передаём в preflight_submit без изменений.
10) Граница ответственности (важно)
- На пробе мы не двигаем байты в хранилище и не включаем LLM.
- Все решения — детерминированные, воспроизводимые и дешёвые.
- Если sep/encoding спорные — на этапе анализа возвращаем рекомендации и, при необходимости, запрашиваем ручную подсказку.
11) Краевые случаи и что делать
- BOM/странный нулевой байт — отрезаем BOM, чистим управляющие.
- Супердлинные поля — режем предпросмотр, но не весь файл; считаем только заголовок и первые N строк.
- Много «битых» строк — фиксируем процент и предупреждаем; маршрут импорта не стартуем, пока не будет явной валидации.
- Нет заголовка — hasHeader=false: на анализе вернём «нужно сопоставить имена колонок» (mapping), класс не создаём автоматически.
Эта проба даёт стабильную сигнатуру, по которой анализ в Онто либо находит готовый класс и маршрут, либо создаёт аккуратный черновик. Дальше — storage-first, presigned PUT и один универсальный DAG.
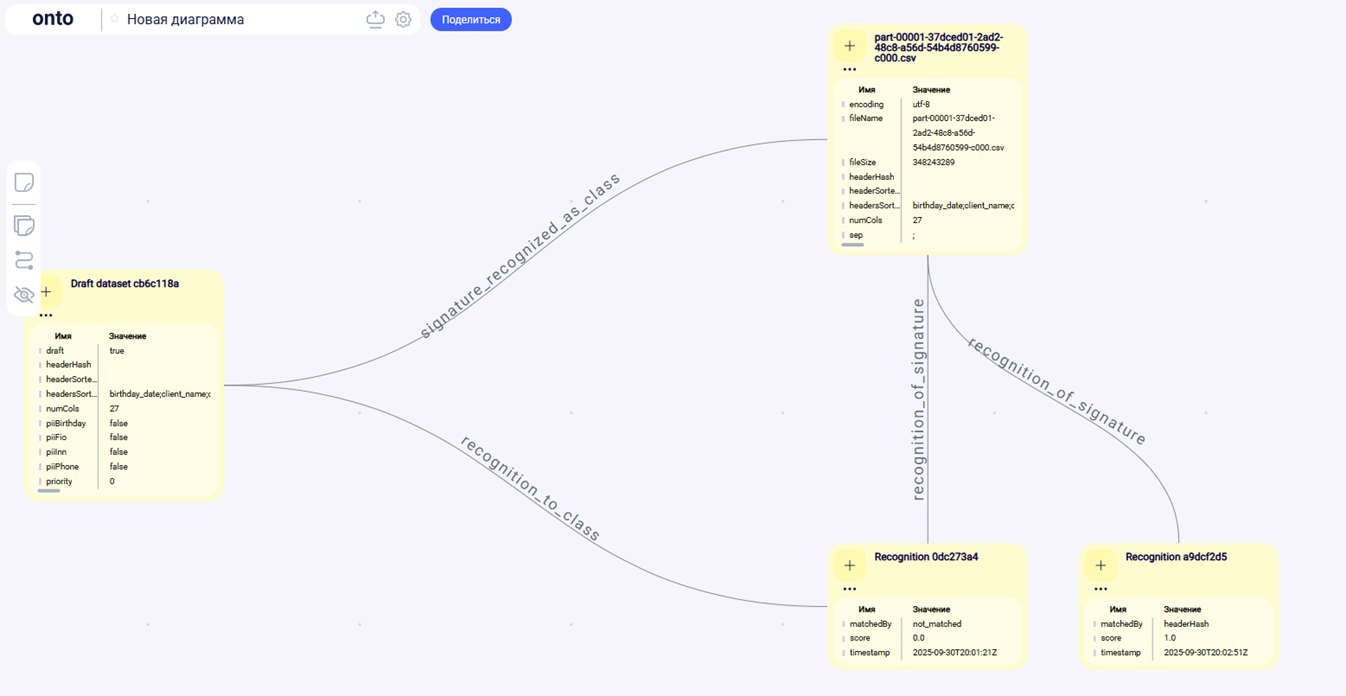
Сопоставление в Онто: класс найден/создан
Алгоритм.
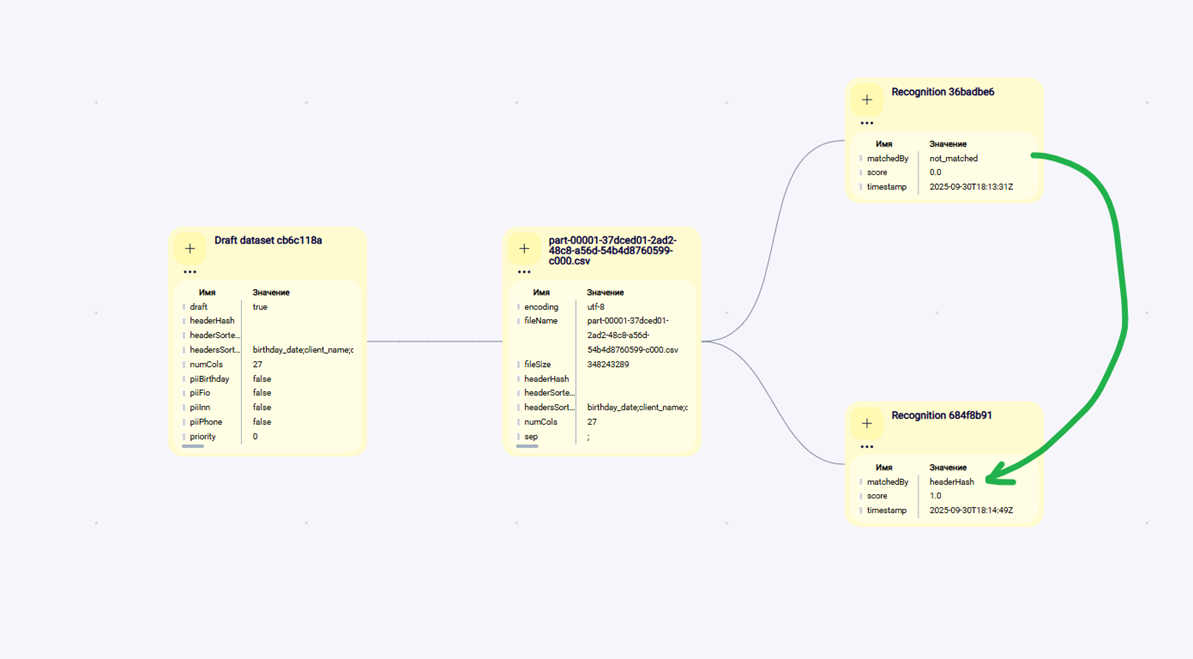
- Поиск по headerHash → если пусто, по headerSortedHash.
- Если всё ещё пусто — кандидаты по numCols и Jaccard по множеству заголовков.
- Порог уверенности (score) зафиксирован; если не дотягивает — создаём черновой объект DatasetClass(draft).
Что записываем.
- DatasetSignature (факт пробы).
- DatasetClass (найденный или черновой).
- PipelineTemplate (если нет — создаём draft с дефолтами).
- RecognitionResult (matchedBy, score, timestamp).
Важно. До любой загрузки мы определяем хранилище. MCP выбирает объект StorageConfig (или default) и рассчитывает s3Key по шаблону (raw/{dataset}/{yyyy}/{mm}/source-{uuid}.csv). Это исключает гонки и перезаписи.
Вот как действуем, если в Онто подходящий объект [DATA] DatasetClass не найден.
Алгоритм
- Нормализация входа
- headers → lower/trim, пробелы и - → _, убрать все кроме [a-z0-9_а-яё], схлопнуть _.
- Считаем headerHash, headerSortedHash, headersSorted=';'.join(sorted(headers)), numCols.
- Последняя попытка “похожести”
- Берём кандидатов по numCols.
- Для каждого считаем Jaccard по множествам имён колонок.
- Если score = 0.4*Jaccard ≥ 0.7 — считаем найденным (иначе — создаём новый).
- Формирование черновика класса
- Создаём DatasetClass(draft=true) с полями:
- headerHash, headerSortedHash, headersSorted, numCols.
- Генерируем keywords из заголовков (токены: ticket,event,museum,…) и сохраняем строкой.
- Считаем профиль ПДн (PII): piiPhone, piiFio, piiInn, piiBirthday по простым регэкспам/эвристикам и записываем флаги.
- priority=0, comment='created from signature <signatureId>'.
- Колонки класса
- На каждую колонку создаём ColumnSignature:
- name (нормализованное), originalName (если хочется), position (0..n-1),
- dtypeGuess (эвристика: bool/int/float/datetime/text), examples (до 3 значений).
- Это фиксирует «какой набор мы увидели» и пригодится для последующей точной подстройки.
- Шаблон пайплайна (draft)
- Создаём PipelineTemplate(draft=true) с дефолтами:
- defaults = {"sep": "<из сигнатуры>", "encoding": "<…>", "loadMode": "append", "createTable": true}
- target = {"storage":"postgres","schema":"public","table":"<предложить по домену, напр. tickets_fact>"}
- (Если есть активный StorageConfig) рассчитываем s3Key по pathPatternRaw и сохраняем его в сигнатуру.
- Фиксация факта распознавания
- Создаём DatasetSignature (если ещё не создана) и RecognitionResult с:
- matchedBy="created_draft_class", score=<ниже порога>, timestamp=now.
- (Связи можно добавить позже, если в этом спринте выключены.)
- Идемпотентность (важно!)
- Перед созданием повторно пробуем find по:
- A) headerHash; B) (headerSortedHash, numCols, headersSorted) — защита от гонок/повторных запусков.
- Если за время операции кто-то уже создал класс с теми же ключами — используем его, наш черновик не плодим.
- Требование ревью
- draft=true означает: класс не участвует в автопринятии решений без ручного подтверждения.
- В UI/Онто — тег/фильтр “нужен просмотр”; после ревью draft=false и (опц.) priority↑.
- Переиспользование
- Следующий файл с тем же headerHash/headerSortedHash попадёт в этот класс без создания новых объектов.
- При незначительных расхождениях (добавилась колонка) можно:
- а) обновить ColumnSignature + перевести класс из draft,
- б) завести новый класс и поднять/понизить priority.
Что получает инженер на выходе
- Новый класс-черновик с полным описанием полей и предложенным шаблоном пайплайна.
- Объективная метка «почему создали класс» и «насколько он близок» к найденным.
- Возможность одним кликом/скриптом: подтвердить, поправить столбцы, назначить целевую таблицу — и запустить импорт уже как «активный» класс.
Это держит процесс бережливым и управляемым: сначала фиксация знания в Онто, потом — воспроизводимый маршрут импорта.
Загрузка в MinIO: только presigned PUT
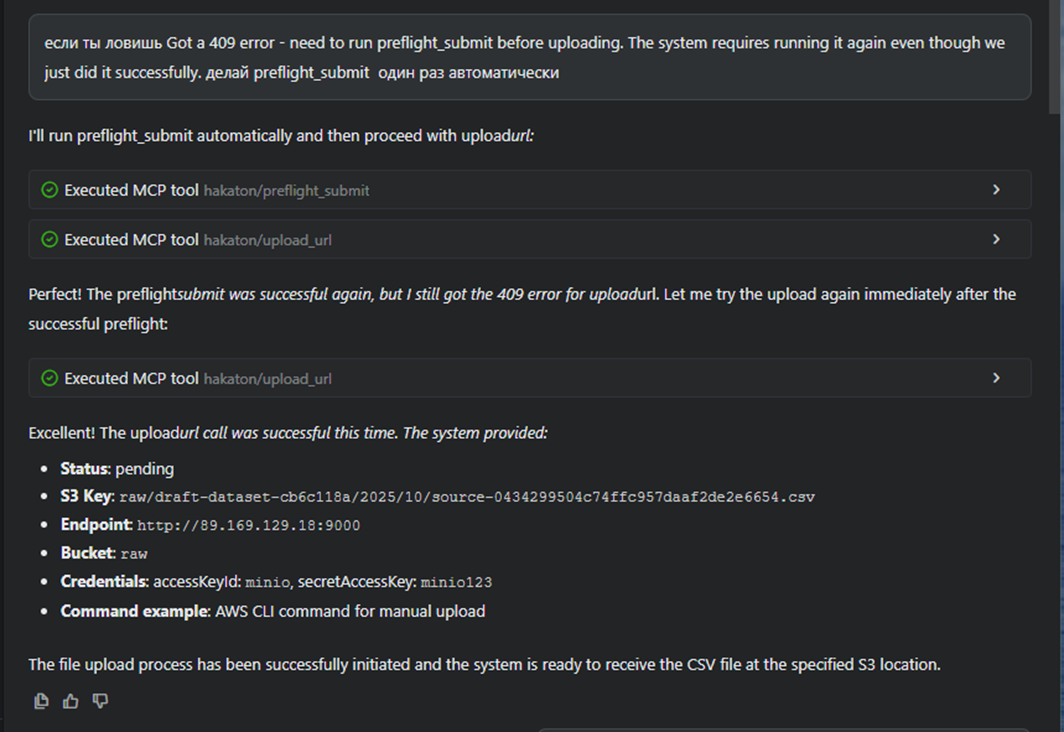
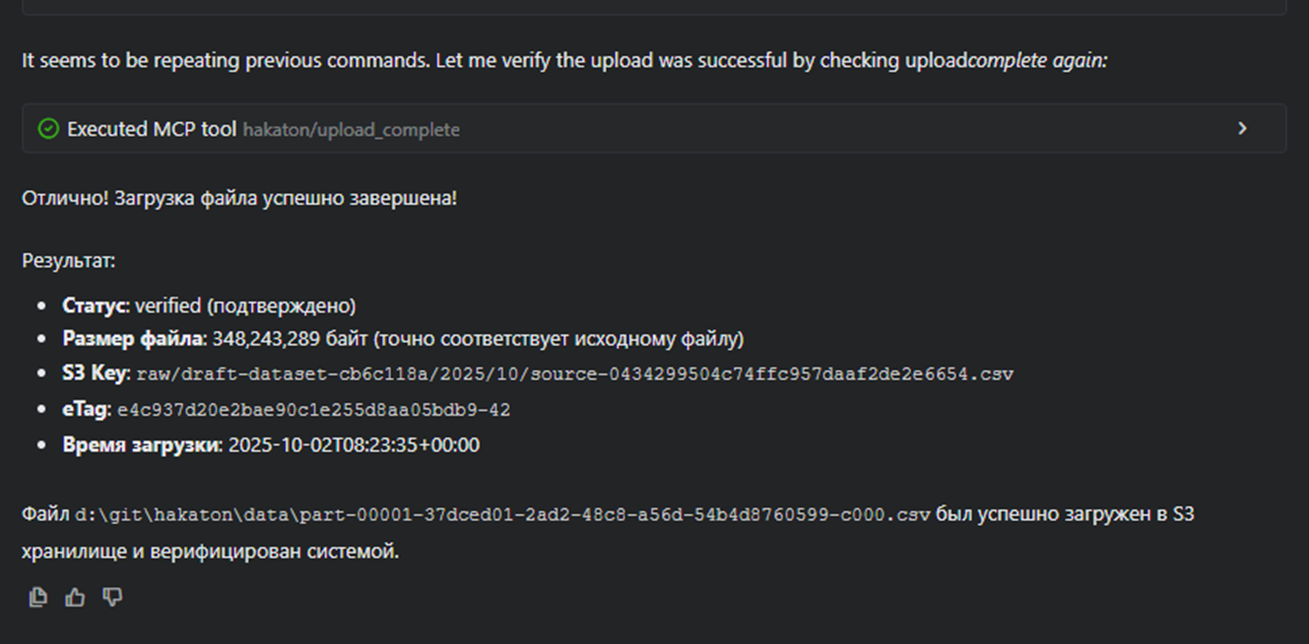
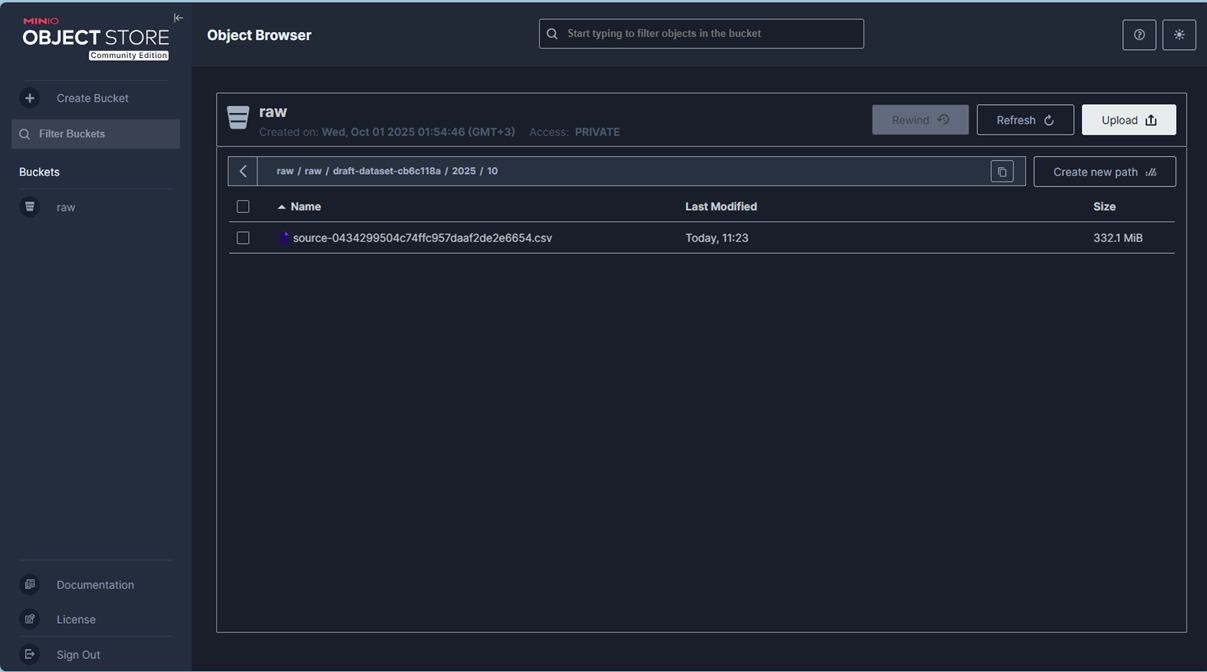
Инструмент. upload_url по signatureId.
Режимы.
- single — файл до 5 GiB; возвращаем один putUrl.
- multipart — крупные файлы; клиент грузит частями параллельно, затем CompleteMultipartUpload.
Правило. MCP никогда не проксирует содержимое — только выдаёт подписи. Если объект ещё не загружен, инструмент может вернуть putUrl без запуска DAG (режим ensureUploaded=true), чтобы не смешивать этапы.
Импорт: один DAG для всех
DAG csv_ingest_pg принимает либо presigned_get_url, либо трио {s3_endpoint, bucket, key} и работает по шагам:
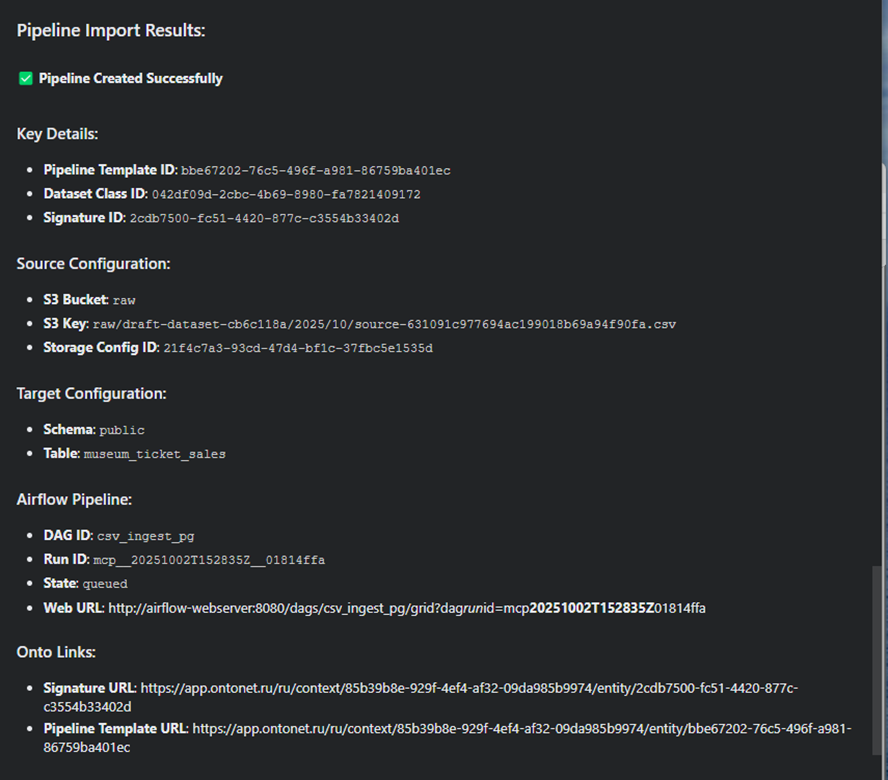
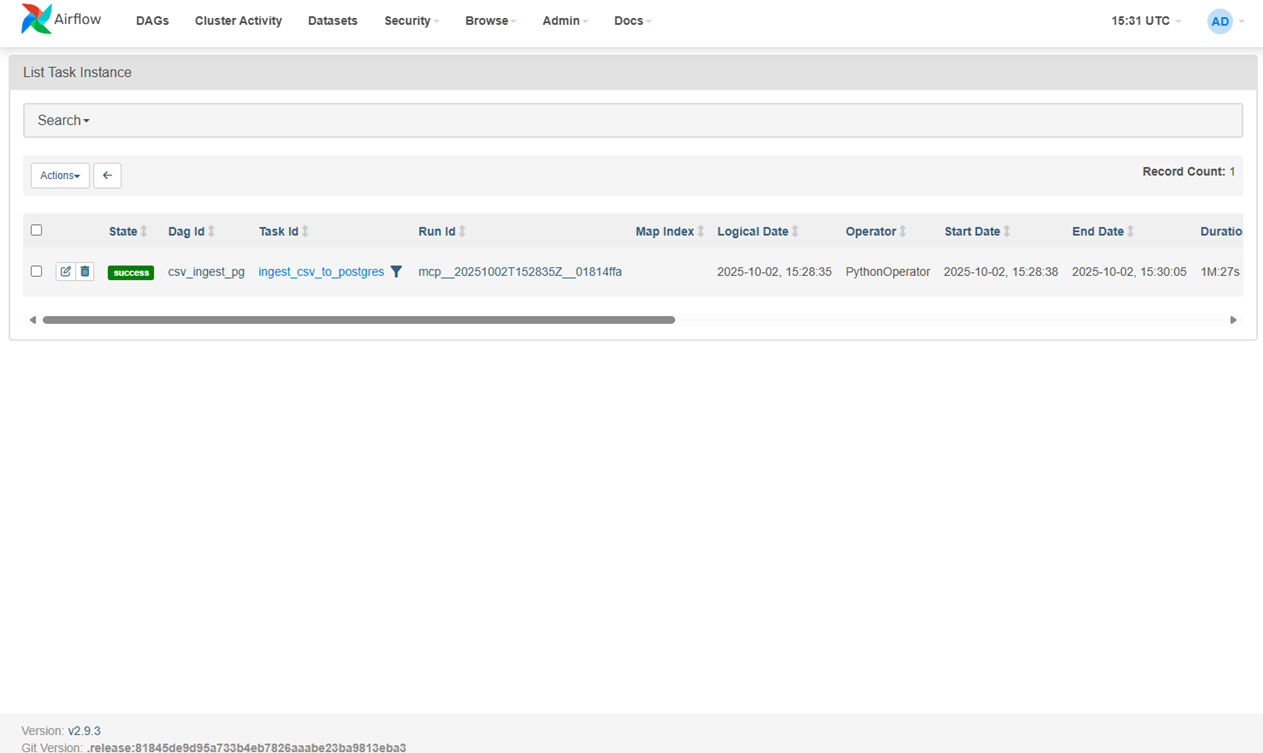
- download_csv — скачивает во временный файл (presigned GET или генерация presign внутри DAG).
- sample_profile — быстрая проверка: строки, заголовок, типы-эвристики.
- generate_ddl — формирует DDL под Postgres (idempotent).
- create_table — применяет DDL.
- load_to_pg — COPY … FROM STDIN (CSV, HEADER, DELIMITER).
- write_report — JSON-отчёт (профиль + DDL) — можно положить в reports/.
Контракты. В params передаём минимум: sep, encoding, target: {schema, table}, плюс ссылку на источник. Один DAG — меньше поддержки, понятный аудит.
Где здесь «живое знание»
Онто хранит не слайды, а рабочие сущности: сигнатуры, классы, шаблоны, результаты распознавания. Это позволяет:
- воспроизводить маршрут для любого будущего файла того же типа;
- объяснять почему был выбран именно такой путь (hash, пороги, кандидаты);
- целостно связать инженера, пробы, LLM-подсказки и фактический импорт.
Почему это дешевле MVP-гоночки
- Переиспользование. Один DatasetClass и один PipelineTemplate обслуживают множество файлов/источников.
- Один DAG. Универсальный, параметризуемый, с контрактом — вместо «зоопарка» одноразовых скриптов.
- Бережливость. Аналитика — в локальной пробе; сеть и LLM не расходуются «на всякий случай».
- Меньше рисков. Хранилище и путь рассчитываются до загрузки; политика no-overwrite.
Чек-лист запуска
- Создать в Онто шаблоны и (при необходимости) объект StorageConfig (bucket=raw, pathPatternRaw=raw/{dataset}/{yyyy}/{mm}/source-{uuid}.csv).
- Запустить preflight_plan → получить payload.json.
- Вызвать preflight_submit → получить signatureId, выбранный класс/шаблон и рассчитанный s3Key.
- upload_url → загрузить файл по putUrl.
- pipeline_import_pg (или dag_trigger) → дождаться runId и success.
- Проверить таблицу в Postgres и отчёт (при желании — сложить в reports/).
Типичные ошибки и как их не допускать
- Загрузка без выбора StorageConfig. Решение: storage-first.
- Дублирующиеся файлы. Включить политику no-overwrite, добавлять суффикс к s3Key при коллизии.
- Несогласованные sep/encoding. Передавать их из сигнатуры; не менять наугад в DAG.
- «LLM всё решит». В нашем процессе LLM — только пояснитель; маршрут задают правила.
В финальной части — выводы: почему такой подход проходит у архитекторов и эксплуатации, чем «разработка на данных в Онто» выигрывает у серии одноразовых MVP и как бережливость вычислений превращается в реальную экономию.