Готовлю пространство: выбираю, где будет жить словарь
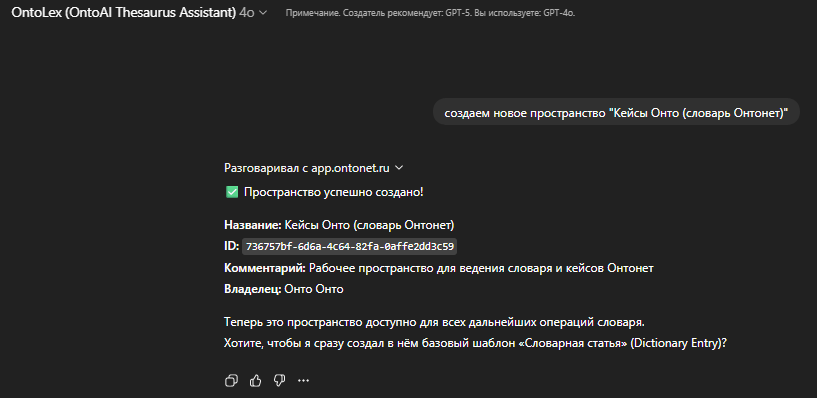
Перед тем как разобрать документ, я всегда отвечаю на один вопрос: где именно будет жить этот словарь — в новом пространстве или прямо в существующей модели.
Если это новое исследование или отдельный кейс, мне часто важен «чистый эксперимент». В таком случае я создаю отдельное пространство. Это как завести новую тетрадь: никакой старой разметки, никаких случайных пересечений с тем, что уже было. Всё, что появится в словаре, будет происходить только из этого документа. Такое пространство удобно, когда нужно увидеть исходную структуру смыслов как она есть, без подсказок и искажений от предыдущих проектов.
Но иногда правильнее сделать наоборот.
Иногда словарь нужен не в новом контексте, а прямо внутри уже сложившейся модели. В живой, нагруженной онтологии, где и так много сущностей, связей, диаграмм. В таких случаях OntoLex позволяет аккуратно развернуть словарную модель прямо поверх текущего графа — и это работает как семантическая санация:
- улучшается качество ссылочных данных (меньше «висячих» ссылок и разнородных формулировок);
- появляются однозначные определения там, где раньше была только коллективная интуиция;
- исчезают дубликаты сущностей, которые назывались похоже, но жили отдельно;
- связи между объектами становятся более строгими и осмысленными;
- AI-агенты перестают «угадывать по ситуации» и начинают опираться на формализованный язык.
В таком режиме словарь не просто фиксирует терминологию, а оздоравливает существующую модель: вытаскивает на свет всё, что раньше держалось на устных договорённостях.
По сути, у меня есть два равноправных сценария:
- новое исследование → новое пространство и словарь, который растёт из одного источника;
- укрепление текущей системы → словарь поверх существующего графа, который выпрямляет и связывает термины.
И ценность OntoLex как раз в том, что он делает оба сценария нормальными:
он одинаково честно работает и в пустом контексте, и в зрелой онтологии. В одном случае мы формируем новую семантику, в другом — приводим в порядок и усиливаем ту, что уже есть.
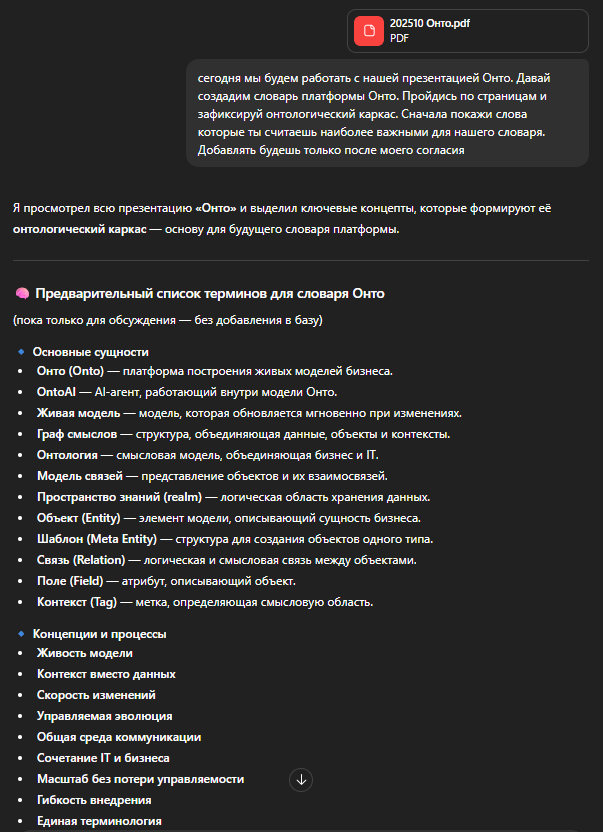
Формирую модель классов: ключевые термины, принципы, ценности, концепции
Как только пространство определено, я перехожу к первому по-настоящему конструктивному шагу — формированию структуры словаря. Документ в этот момент ещё не «разобран», но будущий каркас смыслов уже начинает проступать.
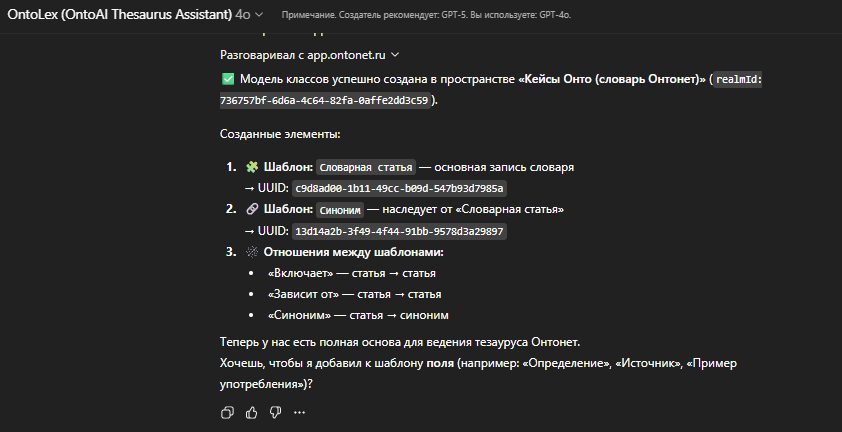
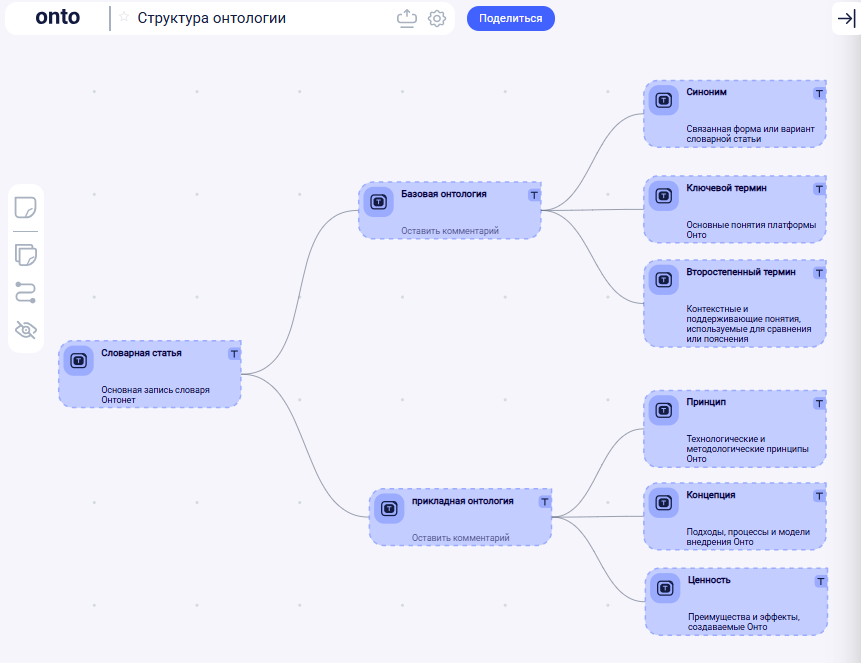
Первое, что делает OntoLex, — предлагает создать базовую сущность: «Словарная статья».
Это тот самый корень, от которого будут наследоваться все остальные понятия. По сути, это договорённость: «всё, что мы дальше называем термином, будет жить в этом семействе».
Дальше начинается самое интересное: я читаю документ не как текст, а как поле будущей онтологии и пытаюсь почувствовать, какие типы знаний в нём вообще присутствуют. В презентациях, особенно продуктовых и архитектурных, почти всегда всплывает знакомый набор:
- ключевые термины — фундаментальные сущности предметной области («Онто», «AI-агент», «Живая модель», «пространство знаний» и т.п.);
- принципы — опорные идеи, на которых строится подход;
- концепции — сущности среднего уровня: процессы, шаблоны, механизмы, состояния;
- ценности — эффекты и обещания: «скорость изменений», «устойчивость системы», «дешёвые изменения», «контроль над изменениями»;
- второстепенные термины — полезные, но не несущие конструкцию понятия;
- синонимы — альтернативные названия, исторические ярлыки и разные языковые формы для одного смысла.
Я даю команду OntoLex, и он за секунды поднимает всю эту конструкцию: создаёт классы, наследует их от базовой «Словарной статьи» и готовит почву для наполнения. В этот момент очень отчётливо ощущается, как появляется скелет будущей онтологии: у модели появляется не просто список слов, а формат, в котором эти слова будут жить.
После этого я почти всегда дорабатываю структуру руками. В случае с презентацией Онто я ввёл разделение на:
- базовую онтологию — понятия платформы как системы (что такое Онто, OntoAI, что такое граф смыслов, живая модель и т.п.),
- прикладную онтологию — понятия внедрения и использования (какие ценности даёт платформа, какие процессы, какие эффекты и сценарии применения).
Это разделение помогает не смешивать «что это за сущность» и «как она помогает бизнесу», а словарю — не захламляться тем, что относится к разным уровням разговора.
Важно понимать: у OntoLex есть и свой стартовый минимум, он не бросает меня в пустое поле. Когда я запускаю ассистента в новом пространстве, он по умолчанию строит минимальную рабочую модель:
- базовый класс «Словарная статья» как главный носитель смысла;
- класс «Синоним» как дочерний;
- набор системных связей вроде «Синоним → Статья», «Статья → Статья» (Includes, Dependency, Synonym) — тот минимум, который позволяет словарю жить как графу, а не как таблице.
Это немного похоже на то, как IDE генерирует каркас проекта: ничего лишнего, только фундамент, который точно пригодится.
А вот всё остальное — категории терминов, уровни онтологии, дополнительные отношения — рождается уже из контекста документа и моего решения. OntoLex помогает, подсказывает, проверяет дубли, но не навязывает. Он даёт структурный старт, а я превращаю его в полноценную онтологию.
Формирование модели классов — это не подготовительный этап.
Это момент, когда словарь перестаёт быть кучей слов и становится каркасом смысла.
Дальше в этот каркас будут вешаться термины из документа, и структура начнёт нарастать почти автоматически.
Добавляю онтологию источников: документ становится частью модели
Когда каркас словаря выстроен, я перехожу к следующему шагу — делаю сам документ полноправным объектом онтологии.
Пока презентация существует только как PDF или набор слайдов, она — внешний артефакт. Она лежит рядом с моделью, но не внутри неё. Как только я переношу её в граф, она начинает подчиняться тем же правилам, что и любые другие сущности: у неё появляется тип, связи, контекст, происхождение и роль.
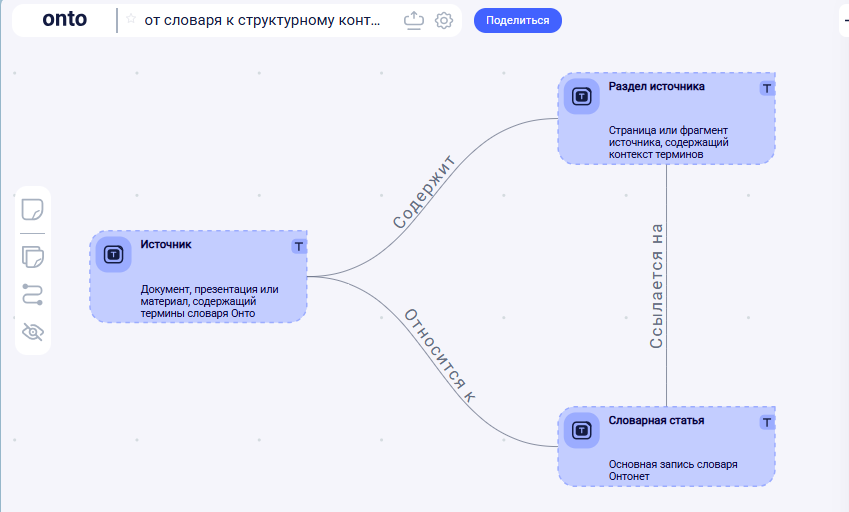
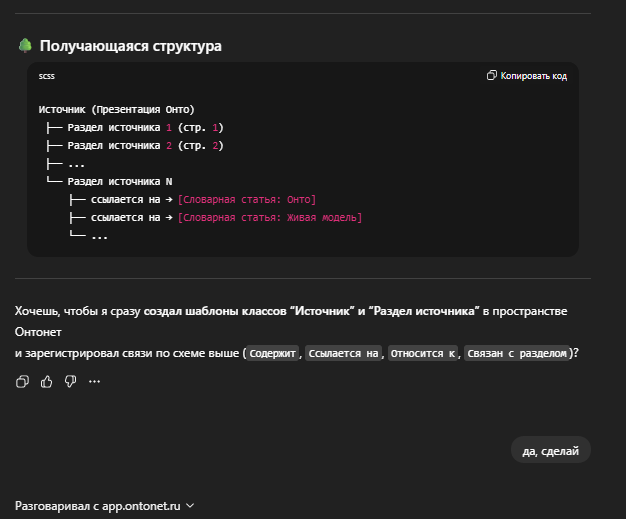
Для этого я ввожу два класса:
- «Источник» — документ целиком: презентация, статья, отчёт, регламент, исследование. Всё то, на что мы ссылаемся, когда задаём вопрос «а где это написано?»
- «Раздел источника» — логический кусок документа: слайд, страница, секция, фрагмент.
Это важно, потому что единица знания почти никогда не «во всём документе», она всегда живёт в конкретном месте: на втором слайде, в третьем разделе, в конкретном абзаце.
OntoLex умеет работать с такой схемой и тут же предлагает завести нужные связи:
- «Содержит» — Источник → Раздел источника;
- «Следующий/предыдущий раздел» — навигация между частями документа;
- «Ссылается на» — Раздел источника → Словарная статья;
- «Относится к источнику» — Словарная статья → Источник (обратная связь).
В этот момент документ перестаёт быть просто входным материалом и становится элементом онтологии. У него есть:
- структура,
- разделы,
- связи,
- роль в модели.
Дальше каждый термин, который мы извлечём, будет иметь не только определение и класс, но и:
- своё происхождение (из какого источника),
- свой контекст появления (на какой странице/слайде),
- свой маршрут внутри документа.
Это даёт очень сильный эффект: словарь становится трассируемым.
Я в любой момент могу открыть термин и увидеть: он появился на Странице 2, связан с такими-то соседними понятиями, а их корень — вот там, на Странице 1.
По сути, это уже не просто структурирование — это маленькая эпистемология.
Модель начинает помнить не только что она знает, но и откуда это знание взялось.
И каждый раз, когда я делаю этот шаг, я думаю:
если бы я пытался держать всё это в Excel, я бы уже давно возненавидел и словари, и документы.
В связке с OntoLex это превращается в спокойный, повторяемый ритуал:
создал Источник, нарезал его на Разделы — и документ плавно растворился в графе, став его частью.
Строю структуру презентации: создаю 16 страниц и связи «Содержит»
Когда классы «Источник» и «Раздел источника» готовы, начинается одна из самых зрелищных фаз — я превращаю сам документ в граф.
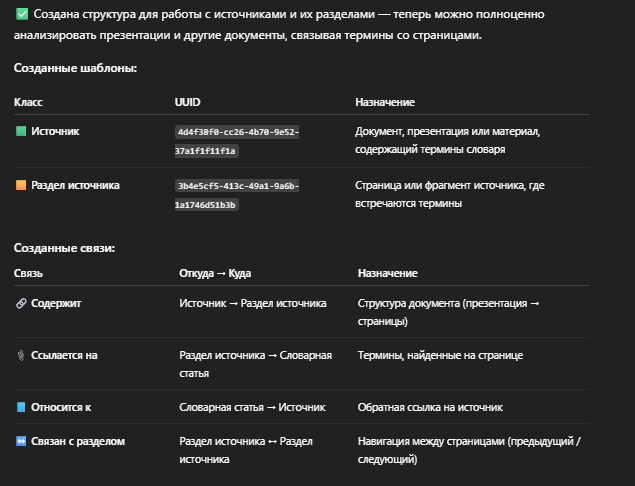
Я создаю объект «Презентация Онто» — это и есть наш Источник.
Дальше OntoLex делает за меня ту часть работы, которую раньше приходилось выполнять вручную, лениво и с ошибками:
- создаёт 16 объектов класса «Раздел источника» — по одному на каждый слайд;
- аккуратно нумерует их и даёт имена, привязанные к содержанию;
- заполняет комментарии, если это нужно;
- строит структурные связи.
На уровне графа это выглядит так:
- «Презентация Онто → содержит → Страница 1»
- «Презентация Онто → содержит → Страница 2»
- …
- «Презентация Онто → содержит → Страница 16»
То есть весь документ получает очевидную иерархию: один Источник, множество Разделов.
На этом OntoLex не останавливается.
Он предлагает создать связи «следующий раздел» / «предыдущий раздел», чтобы модель документа была не просто деревом, а ещё и последовательностью. Появляется цепочка:
Страница 1 → Страница 2 → Страница 3 → … → Страница 16
В итоге у меня в модели — не просто набор страниц, а онтологическая карта документа:
- я вижу, сколько у него разделов;
- как они связаны;
- в каком порядке идут;
- как к ним можно перейти из других частей графа.
В этот момент я открываю диаграмму «Структура презентации» и впервые смотрю на знакомый документ не как на стопку слайдов, а как на живую структуру смысловых фрагментов. Там, где раньше было «ну вот презентация», теперь есть:
- узел Источника,
- гроздь из 16 разделов,
- цепочка последовательности,
- готовые точки, к которым позже пристегнутся термины.
И каждый раз этот жест простой, почти механический шаг — «создать страницы и связи» — даёт одно и то же ощущение:
обычный PDF вдруг начинает вести себя как часть системы знаний, а не как файл, который лежит где-то сбоку.
Главное волшебство: OntoLex читает каждую страницу и извлекает термины
Когда структура документа готова — 16 страниц на своих местах, каждая связана с Источником и с соседями — начинается самая вкусная часть процесса.
Я открываю Страницу 1 презентации.
OntoLex — тоже.
И вот здесь каждый раз срабатывает одинаковое ощущение:
ассистент начинает читать страницу не как текст, а как пространство смыслов.
Он не пытается просто найти «ключевые слова» и подсветить их жёлтым.
Он ищет понятия. Разбирает, что на странице является сущностью, что — ценностью, что — эффектом, а что — просто обвязкой.
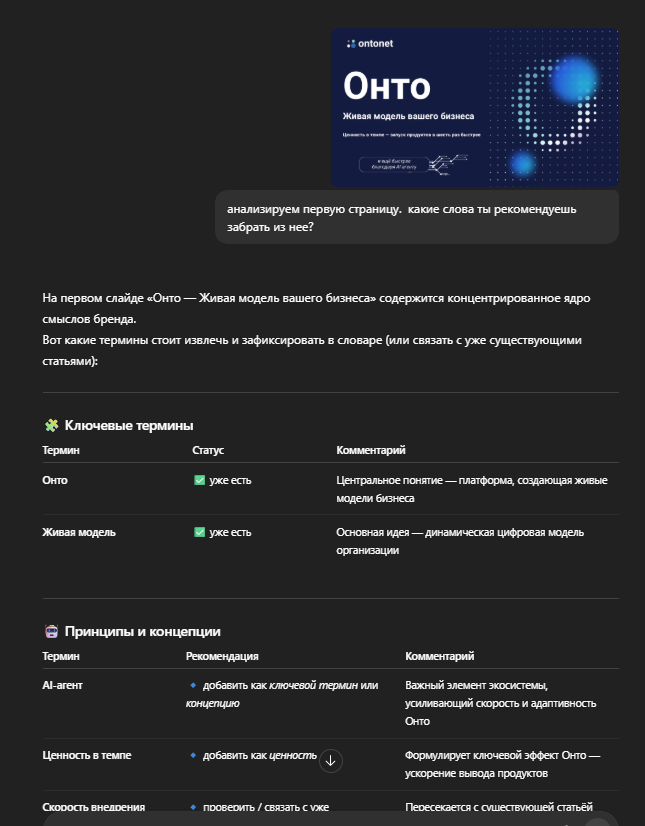
На заглавном слайде он сразу выделяет:
- «Онто» — уже существующий ключевой термин;
- «Живая модель» — тоже ключевой термин;
- «AI-агент» — новый объект, для которого стоит создать статью;
- «Ценность в темпе» — формулировку, которую разумно оформить как отдельную «ценность».
И делает не просто список. Он спрашивает меня:
«Создаём новый термин AI-агент?
К какому классу отнесём?
Свяжем Страницу 1 с этим термином?»
То есть он ведёт себя не как парсер, а как онтологический собеседник.
Я отвечаю «да» — и в этот момент появляются:
- новая словарная статья «AI-агент»;
- связь «Страница 1 → Ссылается на → AI-агент»;
- принадлежность к классу (ключевой термин или участник модели);
- первичный комментарий, который я сразу могу уточнить.
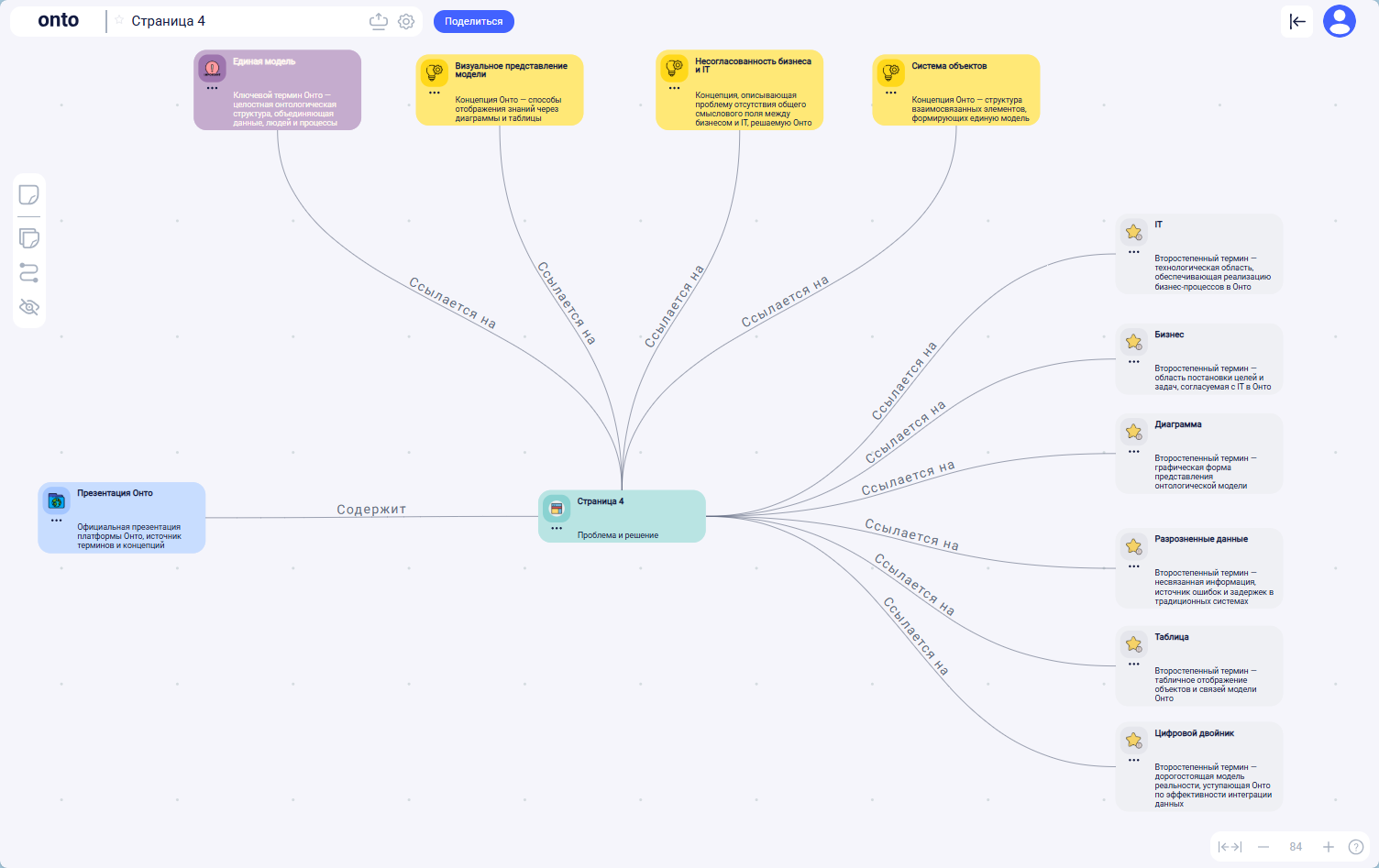
Страница 2 — другая картина.
Там концентрат ценностей и эффектов: «скорость изменений», «устойчивость системы», «контроль над изменениями», «конкурентное преимущество», «усиление людей AI-агентами». OntoLex раскладывает это по полочкам:
- вот список ценностей,
- вот процессы и эффекты,
- вот новые понятия,
- вот уточнение уже существующих.
Если термин уже живёт в словаре (например, «скорость изменений»), ассистент не создаёт дубликат — он предлагает связать раздел с существующей сущностью. Если понятие новое — предлагает завести статью и сразу вставить её в правильное место онтологии.
Каждый раз, когда я подтверждаю его предложения:
- создаём новую статью или используем старую;
- фиксируем связь «Страница N → Ссылается на → Термин»;
- уточняем класс и контекст;
- наращиваем сетку смысловых отношений.
В этот момент словарь перестаёт быть набором карточек и становится структурным контекстом, вплетённым в общий граф.
Третья страница, четвёртая, пятая…
Ритуал повторяется, но ощущение меняется:
документ буквально «распаковывается» в виде сети.
- новые связи появляются как ветки и корни;
- старые понятия обретают глубину, когда для них добавляются новые контексты;
- страницы становятся не картинками, а логическими блоками происхождения знания;
- презентация шаг за шагом растворяется в онтологии.
Это тот самый момент, который я для себя однажды сформулировал так — и специально оставляю эту фразу в тексте:
«Это один из самых красивых шагов, потому что именно здесь OntoLex начинает работать как семантический сканер документа…»
И это действительно так:
ты видишь, как ассистент проходит по документу, слой за слоем, и превращает его из линейной последовательности слайдов в распределённое поле смыслов.
Постепенное нарастание структуры: категории, ценности, концепции, процессы
После нескольких страниц становится видно, что документ больше не живёт как линейная лента слайдов.
Он уже ведёт себя как фрагмент живой онтологии.
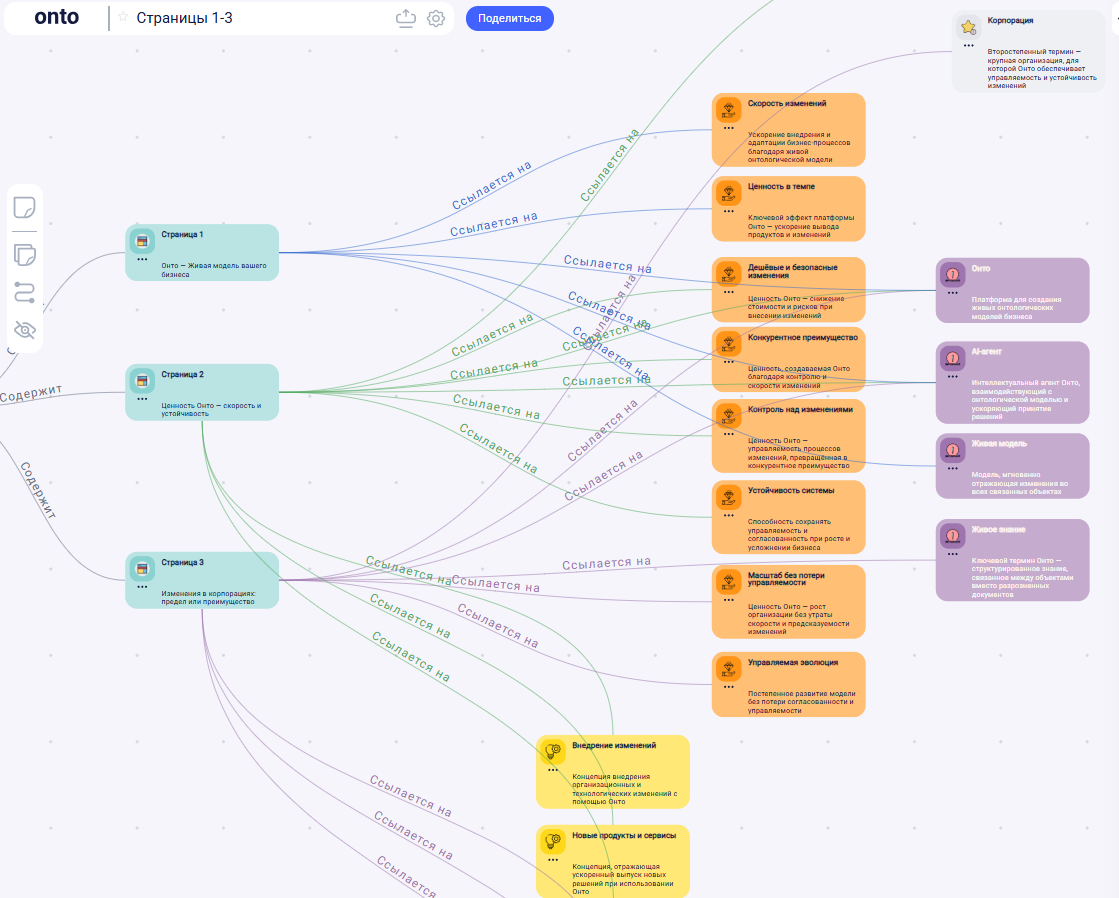
На этом этапе лучше всего подходит слово «нарастание».
Каждый новый термин, каждая связь «Страница → Термин», каждое уточнение класса и контекста — это маленькое действие. Само по себе оно выглядит скромно. Но в сумме эти микро-шаги дают лавинообразный эффект:
- ключевые термины превращаются в узлы высокой связности — к ним тянутся ценности, процессы, контексты;
- ценности собираются в отдельный слой, показывая, за что вообще стоит бороться и что система обещает бизнесу;
- концепции становятся центрами объяснений: вокруг них группируются процессы, состояния, механизмы;
- процессы связывают принципы и результаты: «почему мы так делаем» → «какого эффекта достигаем»;
- второстепенные термины заполняют нюансы, чтобы между крупными блоками не оставалось провалов;
- страницы закрепляют происхождение: видно, из какого фрагмента документа взялся каждый кусочек смысла.
Сначала структура напоминает набор отдельных деревьев.
Через несколько страниц — уже кусты, где ветви начинают переплетаться.
К концу презентации это выглядит как полноценный граф, в котором каждая ветка связана с другими, а смысл не обрывается на границе слайда.
Важно, что это не просто «красиво нарисованная картинка».
Это качественное изменение модели: документ перестаёт быть источником данных и становится частью логики системы.
Я при этом не пишу ни одной строки кода, не руками протягиваю линии между узлами и не сижу ночами в графовом редакторе. Я всего лишь:
- подтверждаю создание нужных статей,
- уточняю классы,
- соглашаюсь или не соглашаюсь на предлагаемые связи,
- иногда добавляю комментарий по смыслу.
Все эти «да» и «так точнее» постепенно вытягивают структуру, и в какой-то момент OntoLex начинает заниматься уже не только извлечением, но и содержательной гигиеной.
И тут раскрывается вторая половина его силы:
- если появляется повторяющееся понятие под другой формулировкой — он предложит связать его с уже существующим;
- если термин похож на существующий, но отличается оттенком смысла — задаст вопрос, в чём именно различие, и поможет развести их аккуратно;
- если термин одновременно тянется к нескольким концепциям — покажет, как это отразить в связях, не потеряв ясности;
- если в документе начинают появляться новые эффекты или процессы, которые не вписываются в текущую сетку — предложит расширить онтологию.
Это уже не просто «анализ документа».
Это эволюция модели знаний, которая происходит в ритме текста: страница за страницей, без отдельных «эпических задач по рефакторингу».
В какой-то момент ловишь себя на том, что структура, которую ты бы вручную строил днями, выросла сама — потому что каждый крошечный шаг был сделан в правильной онтологической рамке.
Продолжение Семантический ритуал: как я извлекаю смысл из документов Часть 3 - "Заключение"